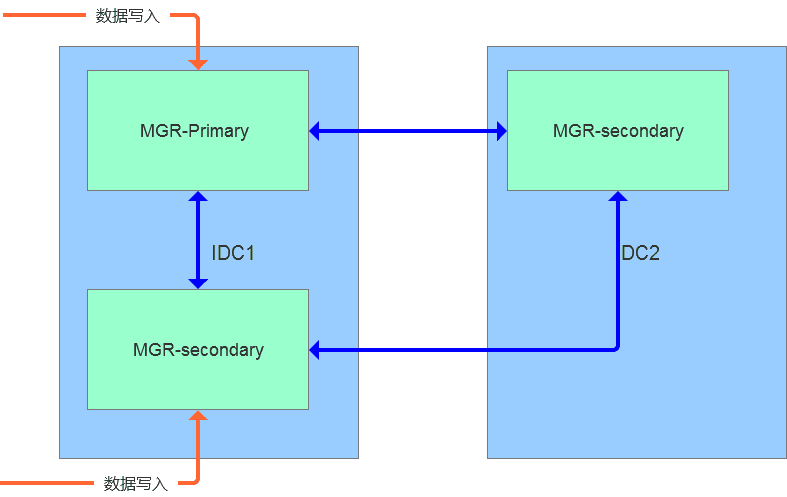
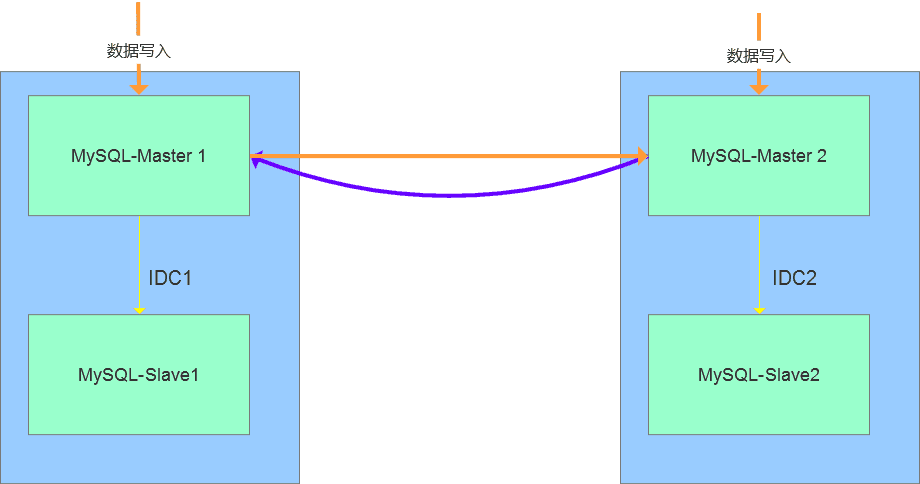
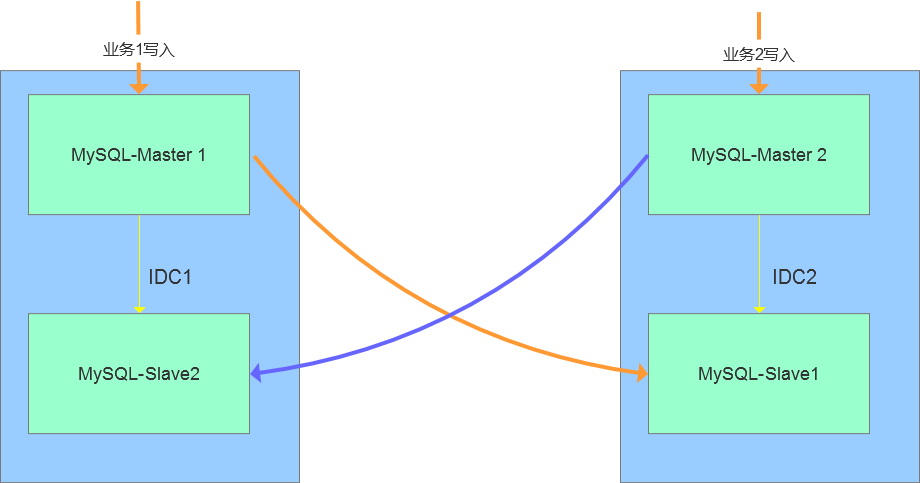
MGR全称MySQL Group Replication(Mysql组复制),是MySQL官方于2016年12月推出的一个全新的高可用与高扩展的解决方案。MGR提供了高可用、高扩展、高可靠的MySQL集群服务。在MGR出现之前,用户常见的MySQL高可用方式,无论怎么变化架构,本质就是Master-Slave架构。MySQL 5.7版本开始支持无损半同步复制(lossless semi-syncreplication),从而进一步提示数据复制的强一致性。
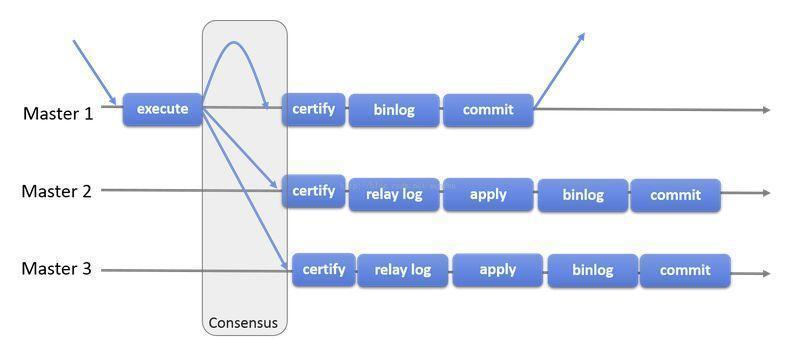
MySQL Group Replication(MGR)是MySQL官方在5.7.17版本引进的一个数据库高可用与高扩展的解决方案,以插件形式提供。MGR基于分布式paxos协议,实现组复制,保证数据一致性。内置故障检测和自动选主功能,只要不是集群中的大多数节点都宕机,就可以继续正常工作。提供单主模式与多主模式,多主模式支持多点写入。
为什么需要使用innodb引擎呢?在MySQL Group Replication中,事务以乐观形式执行,但是在提交时检查冲突,如果存在冲突,则会在某些实例上回滚事务,保持各个实例的数据一致性,那么,这就需要使用到事务存储引擎,同事Innodb提供一些额外的功能,可以更好的管理和处理冲突,所以建议 业务使用表格使用inndb存储引擎,类似于系统表格mysql.user使用MyISAM引擎的表格,因为极少修改及添加,极少出现冲突情况。
npm config set registry=https://registry.npm.taobao.org npm config set sass_binary_site=https://npm.taobao.org/mirrors/node-sass/ npm config set phantomjs_cdnurl=https://npm.taobao.org/mirrors/phantomjs/ npm config set electron_mirror=https://npm.taobao.org/mirrors/electron/
yarn淘宝源
yarn config set sass_binary_site https://npm.taobao.org/mirrors/node-sass/
yarn config set phantomjs_cdnurl https://npm.taobao.org/mirrors/phantomjs/
yarn config set electron_mirror https://npm.taobao.org/mirrors/electron/