使用命令显示隐藏文件
sudo chflags nohidden opt
隐藏文件命令
sudo chflags hidden opt
使用命令显示隐藏文件
sudo chflags nohidden opt
隐藏文件命令
sudo chflags hidden opt
内核参数overcommit_memory
它是 内存分配策略
可选值:0、1、2。
0, 表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
1, 表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
2, 表示内核允许分配超过所有物理内存和交换空间总和的内存
什么是Overcommit和OOM
Linux对大部分申请内存的请求都回复”yes”,以便能跑更多更大的程序。因为申请内存后,并不会马上使用内存。这种技术叫做 Overcommit。当linux发现内存不足时,会发生OOM killer(OOM=out-of-memory)。它会选择杀死一些进程(用户态进程,不是内核线程),以便释放内存。
当oom-killer发生时,linux会选择杀死哪些进程?选择进程的函数是oom_badness函数(在mm/oom_kill.c中),该 函数会计算每个进程的点数(0~1000)。点数越高,这个进程越有可能被杀死。每个进程的点数跟oom_score_adj有关,而且 oom_score_adj可以被设置(-1000最低,1000最高)。
解决方法:
很简单,按提示的操作(将vm.overcommit_memory 设为1)即可:
有三种方式修改内核参数,但要有root权限:
(1)编辑/etc/sysctl.conf ,改vm.overcommit_memory=1,然后sysctl -p使配置文件生效
(2)sysctl vm.overcommit_memory=1
(3)echo 1 > /proc/sys/vm/overcommit_memory
文章目录
使用docker时,
每次停止docker systemctl stop docker 命令执行完都会提示
Warning: Stopping docker.service, but it can still be activated by: docker.socket
目前找到的问题原因是:
This is because in addition to the docker.service unit file, there is a docker.socket unit file… this is for socket activation. The warning means if you try to connect to the docker socket while the docker service is not running, then systemd will automatically start docker for you. You can get rid of this by removing /lib/systemd/system/docker.socket… you may also need to remove -H fd:// from the docker.service unit file.
这是因为除了docker.service单元文件,还有一个docker.socket单元文件…docker.socket这是用于套接字激活。
该警告意味着:如果你试图连接到docker socket,而docker服务没有运行,系统将自动启动docker。
你可以删除 /lib/systemd/system/docker.socket
从docker中 docker.service 文件 删除 fd://,即remove -H fd://
如果不想被访问时自动启动服务
输入命令:
sudo systemctl stop docker.socket
Link: https://blog.csdn.net/weixin_43885975/article/details/117809901
文章目录
systemctl status firewalld
firewall-cmd --state
查看linux哪些程序正在使用互联网
firewall-cmd --permanent --list-services ssh dhcpv6-client
开启
service firewalld start
重启
service firewalld restart
关闭
service firewalld stop
firewall-cmd --list-all
查询端口是否开放
firewall-cmd --query-port=8080/tcp
开放80端口
firewall-cmd --permanent --add-port=80/tcp
firewall-cmd --permanent --add-port=8080-8085/tcp
移除端口
firewall-cmd --permanent --remove-port=8080/tcp
查看防火墙的开放的端口 firewall-cmd --permanent --list-ports
重启防火墙(修改配置后要重启防火墙)
firewall-cmd --reload
参数解释
1、firwall-cmd:是Linux提供的操作firewall的一个工具;
2、--permanent:表示设置为持久;
3、--add-port:标识添加的端口;
Link: https://blog.csdn.net/qq_41153478/article/details/83033688
Binds worker processes to the sets of CPUs. Each CPU set is represented by a bitmask of allowed CPUs. There should be a separate set defined for each of the worker processes. By default, worker processes are not bound to any specific CPUs.
For example,
worker_processes 4; worker_cpu_affinity 0001 0010 0100 1000;
binds each worker process to a separate CPU, while
worker_processes 2; worker_cpu_affinity 0101 1010;
binds the first worker process to CPU0/CPU2, and the second worker process to CPU1/CPU3. The second example is suitable for hyper-threading.
The special value auto (1.9.10) allows binding worker processes automatically to available CPUs:
worker_processes auto; worker_cpu_affinity auto;
The optional mask parameter can be used to limit the CPUs available for automatic binding:
worker_cpu_affinity auto 01010101;
The directive is only available on FreeBSD and Linux.
link: http://nginx.org/en/docs/ngx_core_module.html#worker_cpu_affinity
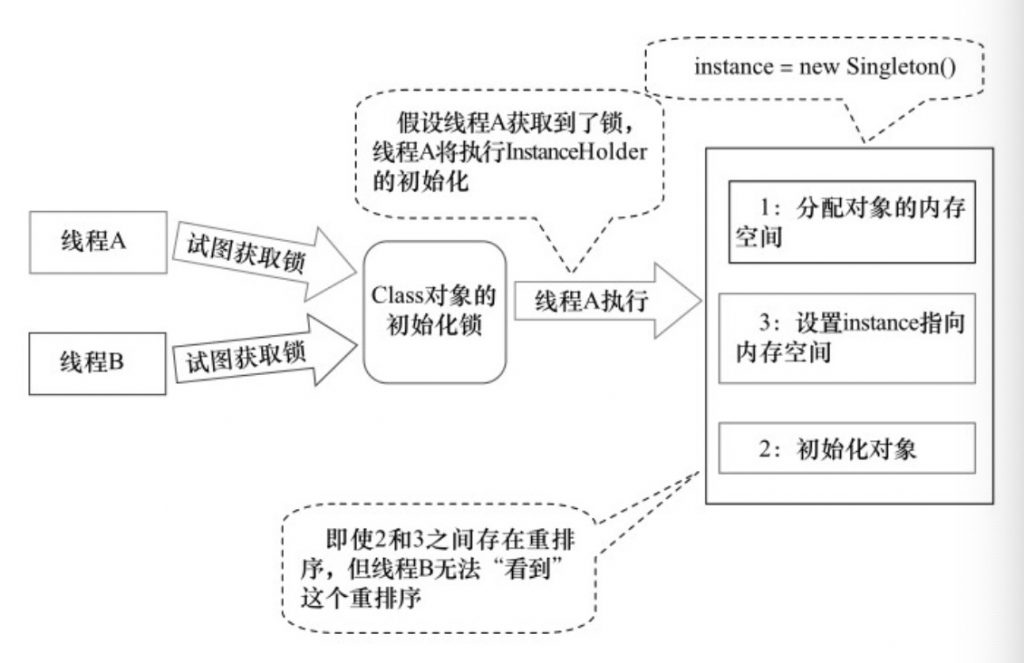
实例化对象在JVM中实际上包含如下指令:
上述步骤在单线程中是没问题的。JVM在指令重排序也不会影响到单线程的执行顺序,但是在多线程环境下就会因为重排序导致出现使用未被初始化完成的对象,指令会被重排序为:
如果线程1执行到了上述的步骤2,线程2执行就会使用未被初始化完成的对象。
public class DoubleCheckedInstance {
private volatile static Instance instance;
public static Instance getInstance() {
if (instance == null) {
synchronized (DoubleCheckedInstance.class) {
if (instance == null) {
instance = new Instance();
}
}
}
return instance;
}
}
关键点:
private volatile static Instance instance;
如果没有volatile关键字,则在实例化Instance对象时会出现指令重排序,从而导致在多线程环境下使用了未被初始化完成的对象。
public class InstanceFactory {
private static class InstanceHolder {
public static Instance instance = new Instance();
}
public static Instance getInstance() {
return InstanceHolder.instance;
}
}JVM在类的初始化阶段(即在Class被加载后,且被线程使用之前),会执行类的初始化。在执行类的初始化期间,JVM会去获取一个锁。这个锁可以同步多个线程对同一个类的初始化。
参考资料:
在Ubuntu 18.04系统中,在安装有docker-compose时,将无法正常登录。
详情如下:
docker login
Password:
Error saving credentials: error storing credentials - err: exit status 1, out: `Cannot autolaunch D-Bus without X11 $DISPLAY`解决方法,移除掉docker-compose:
sudo apt-get autoremove --purge docker-compose再执行:
docker login
Password:
Login Succeeded从大类上分,虚拟化技术可分为基于硬件的虚拟化和基于软件的虚拟化。
其中,真正意义上的基于硬件的虚拟化技术不多见,少数如网卡中的单根多IO虚拟化(Single Root I/OⅤirtualizationand Sharing Specification,SR-IOⅤ)等技术,也超出了本书的讨论范畴。基于软件的虚拟化从对象所在的层次,又可以分为应用虚拟化和平台虚拟化(通常说的虚拟机技术即属于这个范畴)。其中,前者一般指的是一些模拟设备或Wine这样的软件。后者又可以细分为如下几个子类:
Docker以及其他容器技术都属于操作系统的虚拟化这个范畴。
Docker和常见的虚拟机方式的差异比较:
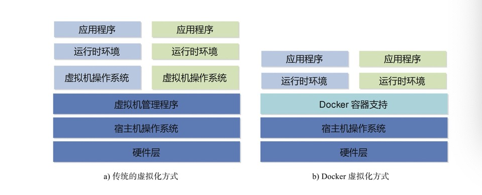
Docker和传统的虚拟机方式的不同之处–传统方式是在硬件层面实现虚拟化,需要有额外的虚拟机管理应用和虚拟机操作系统层
在制作Ubuntu的Docker镜像时,安装tzdata库会弹出交互提示,中断了镜像文件制作。
解决方法,采用静默安装的方式:
ENV DEBIAN_FRONTEND=non-interactive
RUN apt-get update && apt-get -y install tzdata如果代码中使用了线程池,一种优雅停机的方式就是注册一个JVM钩子函数,在JVM进程关闭之前,先将线程池关闭,及时释放资源。
public static NamesrvController start(final NamesrvController controller) throws Exception {
if (null == controller) {
throw new IllegalArgumentException("NamesrvController is null");
}
boolean initResult = controller.initialize();
if (!initResult) {
controller.shutdown();
System.exit(-3);
}
Runtime.getRuntime().addShutdownHook(new ShutdownHookThread(log, new Callable<Void>() {
@Override
public Void call() throws Exception {
controller.shutdown();
return null;
}
}));
controller.start();
return controller;
}